# canal集群搭建
# 一、环境准备
- zookeeper集群服务
- jdk11(canal 1.1.6 运行环境)
# 1、zookeeper搭建
为了省事,这里直接使用docker-compose(在test-01 ,test-02 服务器运行即可)
version: '3'
services:
zookeeper-canal-1:
image: zookeeper:3.4.11
ports:
- "2181:2181"
- "2888:2888"
- "3888:3888"
container_name: zookeeper-canal-1
restart: always
volumes:
- ./zoo/data:/data
- ./zoo/datalog:/datalog
environment:
TZ: Asia/Shanghai
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=172.18.15.8:2888:3888 server.2=172.18.15.10:2888:3888
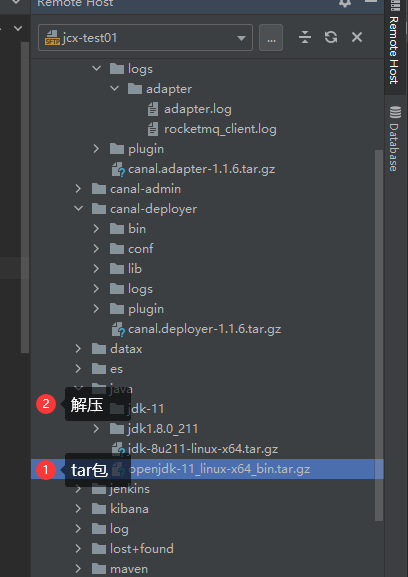
# 2、jdk11

# 下载完成后复制进 /data0/java 目录
cd /data0/java
tar -zxvf openjdk-11_linux-x64_bin.tar.gz
# 二、下载并安装 canal1.1.6
# 1、创建目录
cd /data0
mkdir canal-deployer
mkdir canal-adapter
mkdir canal-admin
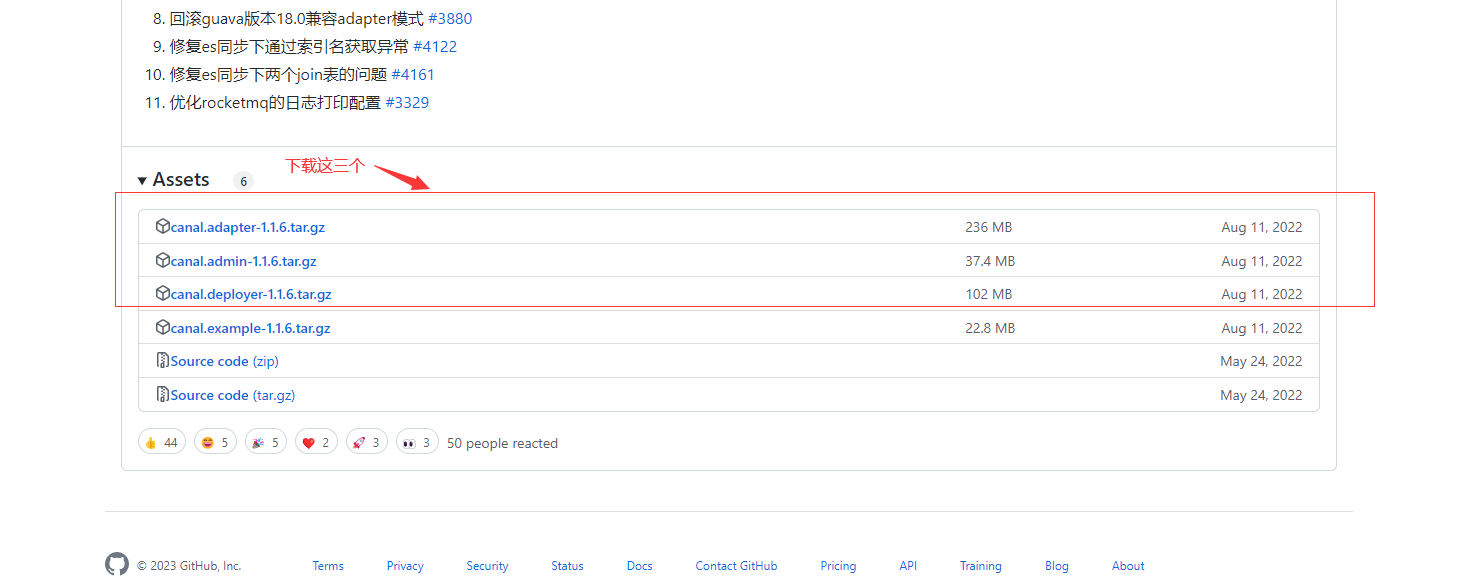
# 2、分别把下载好的安装包上传至对应文件夹并解压
cd /data0/canal-deployer
tar -zxvf canal.deployer-1.1.6.tar.gz
cd /data0/canal-adapter
tar -zxvf canal.adapter-1.1.6.tar.gz
cd /data0/canal-admin
tar -zxvf canal.admin-1.1.6.tar.gz
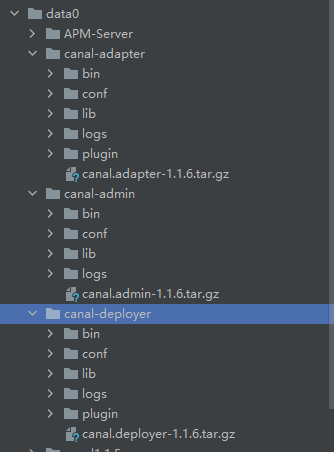
- 解压后目录如下
# 3、修改java环境
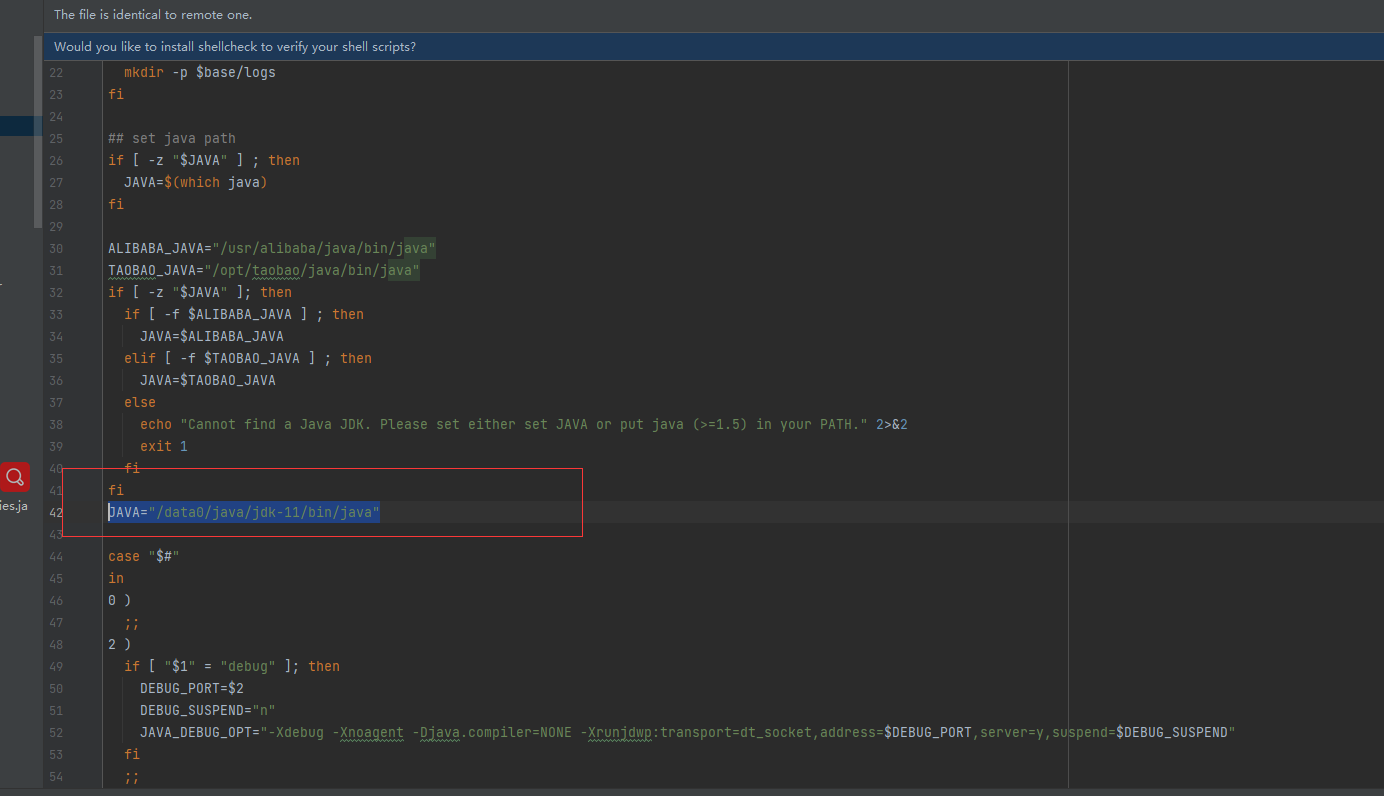
找到 三个项目解压后的bin目录文件下的startup.sh文件
比如:
cd /data0/canal-adapter/bin
加入如下代码
JAVA="/data0/java/jdk-11/bin/java"
- 如图
- 依次操作其他三个项目
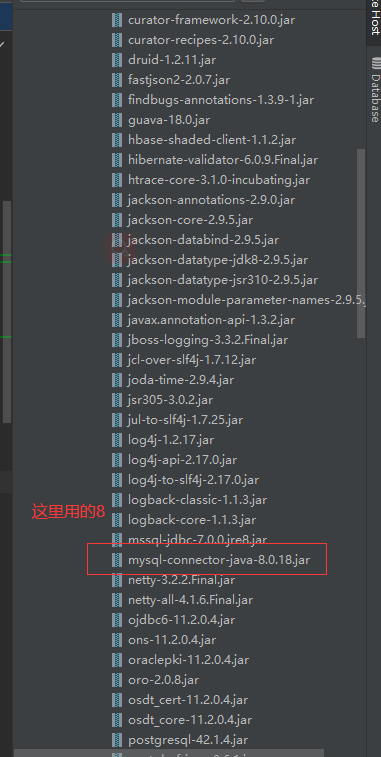
# 4、替换mysql连接池
以 adapter 为例
cd /data0/canal-adapter/lib
*以下是替换后的目录
# 三、 服务端deployer搭建
# 1、 创建实例
cd /data0/canal-deployer
cp -R conf/example conf/cluster
# 2、修改实例内容
vim conf/cluster/instance.properties
- 修改内容:
# 每个canal节点的slaveId保持唯一,在1.0.26版本后已经能够自动生成了, 无需设置
# canal.instance.mysql.slaveId=1
# 设置binlog同步开始位置 (自行替换)
canal.instance.master.address=192.168.244.17:3306
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=0
canal.instance.master.timestamp=1665038153854
# 数据源账号密码 (自行替换)
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
mysql数据同步起点说明:
•canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动 •canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动 •不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
# 3、 修改配置文件canal.properties
- 修改内容
# 设置canal服务端IP (不同服务器不同)
canal.ip =172.18.15.8
# zk地址,多个地址用逗号隔开
canal.zkServers =172.18.15.8:2181,172.18.15.10:2181
# 实例名称
canal.destinations = cluster
# 持久化模式采用zk
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
# 4、启动
./bin/startup.sh
参考上述配置调整deployer节点2,注意deployer服务ip调整为当前节点的ip
启动两个节点,需要注意的是,启动第二个节点的时候是不会启动成功的,如我们上述所说同时只会有一个canal服务运行,当另一个canal服务宕机时该备用节点会自动启动的
# 四、客户端adapter配置
# 1、修改配置文件application.yml
cd /data0/canal-adapter
vim conf/application.ym
*修改内容,所需调整项已用【】 标识
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
# zk地址【1】
zookeeperHosts: 192.168.244.1:2181
syncBatchSize: 1000
# 出现报错时的重试次数
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
# deployer服务端地【2】
# canal.tcp.server.host: 127.0.0.1:11111
# zk地址【3】
canal.tcp.zookeeper.hosts: 192.168.244.1:2181
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources:
# 源数据库地址,可配置多个
canalDs: # 命名自定义【4】
url: jdbc:mysql://192.168.244.17:3306/canal_test?useUnicode=true
username: canal
password: canal
canalAdapters:
- instance: cluster # 服务端配置的实例名称【5】
groups:
- groupId: g1
outerAdapters:
# 开启日志打印
- name: logger
# 配置目标数据源【5】
-
key: es
# es7 or es6
name: es7
hosts: http://192.168.244.11:9200 # 127.0.0.1:9300 for transport mode
properties:
mode: rest # or rest or transport
# es账号密码
security.auth: elastic:elastic # only used for rest mode
# es集群名称
cluster.name: blade-cluster
# 2、 创建同步配置文件canal.yml
vim conf/es7/canal.yml
TIP
注意:这里的sql 必须要起别名,不然会报错
dataSourceKey: defaultDS # 这里的key与上述application.yml中配置的数据源保持一致
destination: cluster # 默认为example,
groupId: g1
esMapping:
_index: canal
_id: canalId
upsert: true
sql: "SELECT a.canalId,a.content FROM canal a"
# etlCondition: "where t.update_time>='{0}'"
commitBatch: 3000
- 这里可根据自己的数据库表创建对应的文件,我这里只同步了一张表,es中的索引mappings如下,同步前请提前创建好索引
PUT /canal
{
"mappings": {
"properties": {
"canalId": {
"type": "text"
},
"content": {
"type": "text"
}
}
}
}
- 另一台adapter节点也同样配置
# 3、启动
./bin/startup.sh

# 五、测试数据增量导入
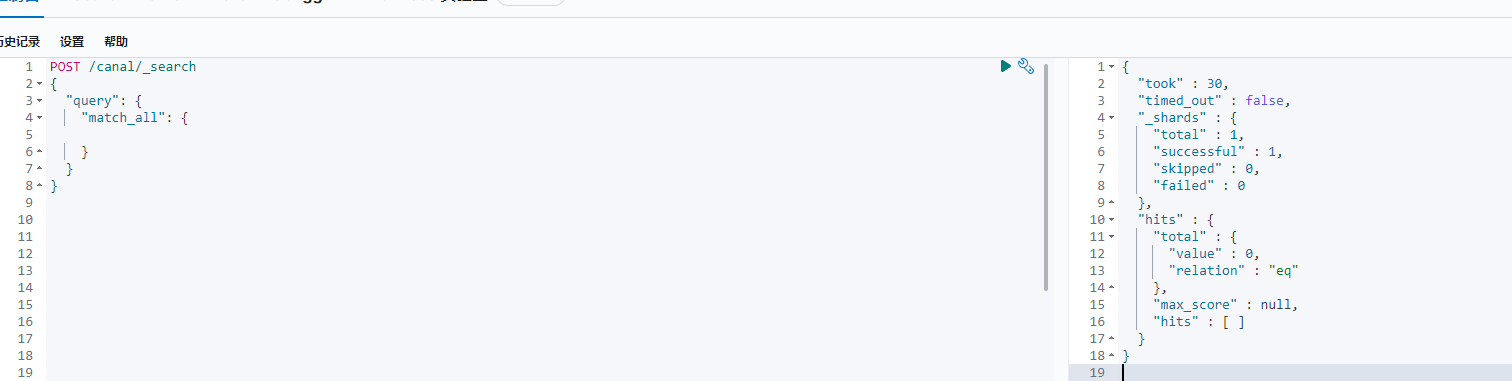
# 1、查看索引数据
POST /canal/_search
{
"query": {
"match_all": {
}
}
}
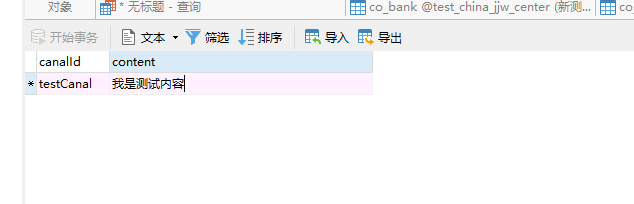
# 2、往canal表添加数据
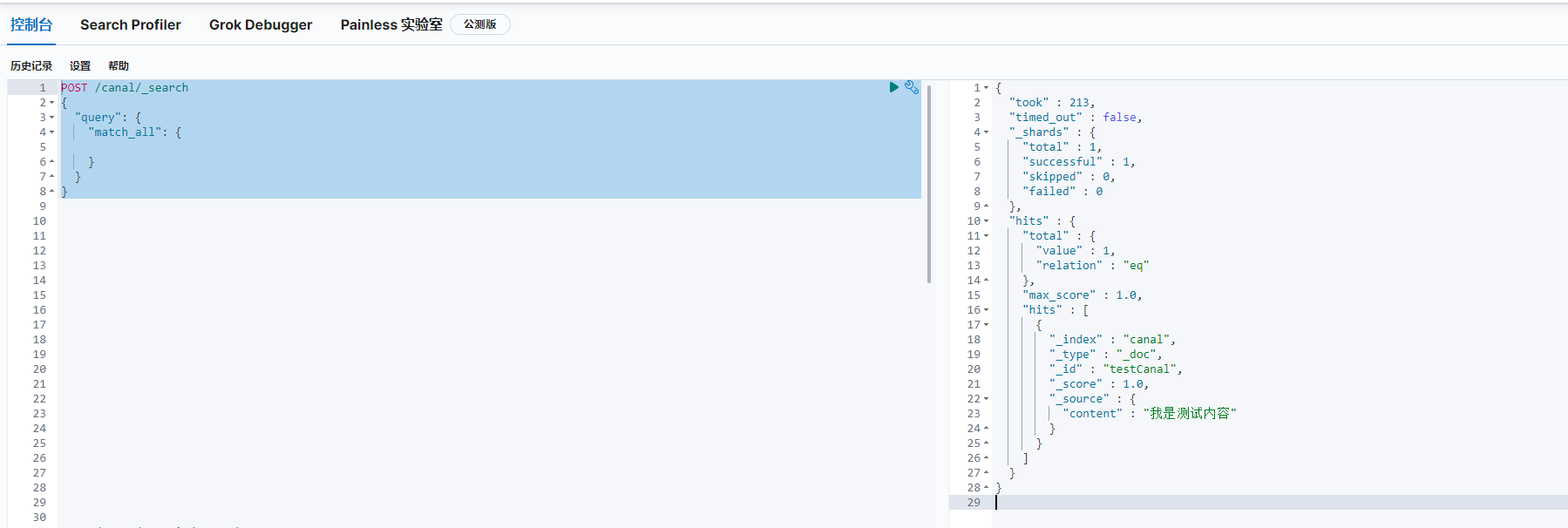
# 3、验证结果
POST /canal/_search
{
"query": {
"match_all": {
}
}
}
# 六、 改成单节点
# 1、修改配置文件canal.properties 修改持久化模式
修改内容
# 使用内存模式(无持久化)
canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
# 或使用文件持久化模式
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
# 2、删掉zookeeper配置
# deployer
vim conf/canal.properties
# 设置canal服务端IP (不同服务器不同)
canal.ip =172.18.15.8
# zk地址,注掉
# canal.zkServers =172.18.15.8:2181,172.18.15.10:2181
# 实例名称
canal.destinations = cluster
# 使用内存模式(无持久化)
canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
# 或使用文件持久化模式
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
# adapter
1、修改配置文件application.yml
cd /data0/canal-adapter
vim conf/application.ym
删除配置文件zookeeperHosts
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
# zk地址【1】
# zookeeperHosts: 192.168.244.1:2181
syncBatchSize: 1000
# 出现报错时的重试次数
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
# deployer服务端地【2】
# canal.tcp.server.host: 127.0.0.1:11111
# zk地址【3】注掉
# canal.tcp.zookeeper.hosts: 192.168.244.1:2181
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources:
# 源数据库地址,可配置多个
canalDs: # 命名自定义【4】
url: jdbc:mysql://192.168.244.17:3306/canal_test?useUnicode=true
username: canal
password: canal
canalAdapters:
- instance: cluster # 服务端配置的实例名称【5】
groups:
- groupId: g1
outerAdapters:
# 开启日志打印
- name: logger
# 配置目标数据源【5】
-
key: es
# es7 or es6
name: es7
hosts: http://192.168.244.11:9200 # 127.0.0.1:9300 for transport mode
properties:
mode: rest # or rest or transport
# es账号密码
security.auth: elastic:elastic # only used for rest mode
# es集群名称
cluster.name: blade-cluster